
Search
On-going Research
갤러리 보기
Search



1. What is singing voice synthesis?

Singing voice synthesis (SVS) is the task of generating a natural singing voice from a given musical score. With the development of various deep generative models, research on synthesizing high-quality singing voices has been emerging recently. As the performance of the SVS improves, there are increasing cases in which the technology is applied to the production of actual music content.
.png&blockId=eb36e24a-94b0-47c3-bd3f-a538558d3466)
2. Challenges
There are various challenges to designing a singing synthesis system that can freely generate high-quality, natural-sounding singing voices.
•
First of all, the problem is that it is difficult to construct a dataset. In general, since singing is difficult to be released due to issues such as copyright, we have limitations in collecting public singing datasets. It is also difficult to access clean singing voices, as many are released with accompaniment. Lastly, singing synthesis requires not only a clean singing voice but also appropriate sheet music information corresponding to it, and the process of annotating it is time-consuming and costly.
•
In order to respond to this problem, 1) research on effectively modeling singing using only small data (LiteSing, Sinsy), 2) research on securing data sets using technologies such as sound source separation and automatic notation from various sound sources existing on the online web (DeepSinger), 3) Research on creating and presenting singing datasets free from copyright issues such as nursery rhymes is being conducted (CSD).
•
In our lab, we collect 200 songs and conduct research using them. First, we purchase an accompaniment MIDI file for K-POP music from a MIDI accompaniment producer, then hire an amateur singer to sing and record the song to the accompaniment. Later, by manually correcting minute differences in timing and pitch between the actual singing and the melody MIDI, the song and score pair data are obtained. Using this data, we are working on singing voice synthesis modeling while at the same time trying to obtain more sophisticated annotations through transcription and alignment studies.
Dataset example (audio, midi stereo)
2.2 Sound quality
•
With advances in speech synthesis studies, generating results of adequate quality in speech synthesis has advanced a lot. However, for singing synthesis technology to be used in real industry, studio quality results are required. Therefore, we are exploring different methods aimed at generating a 44 kHz sound source.
•
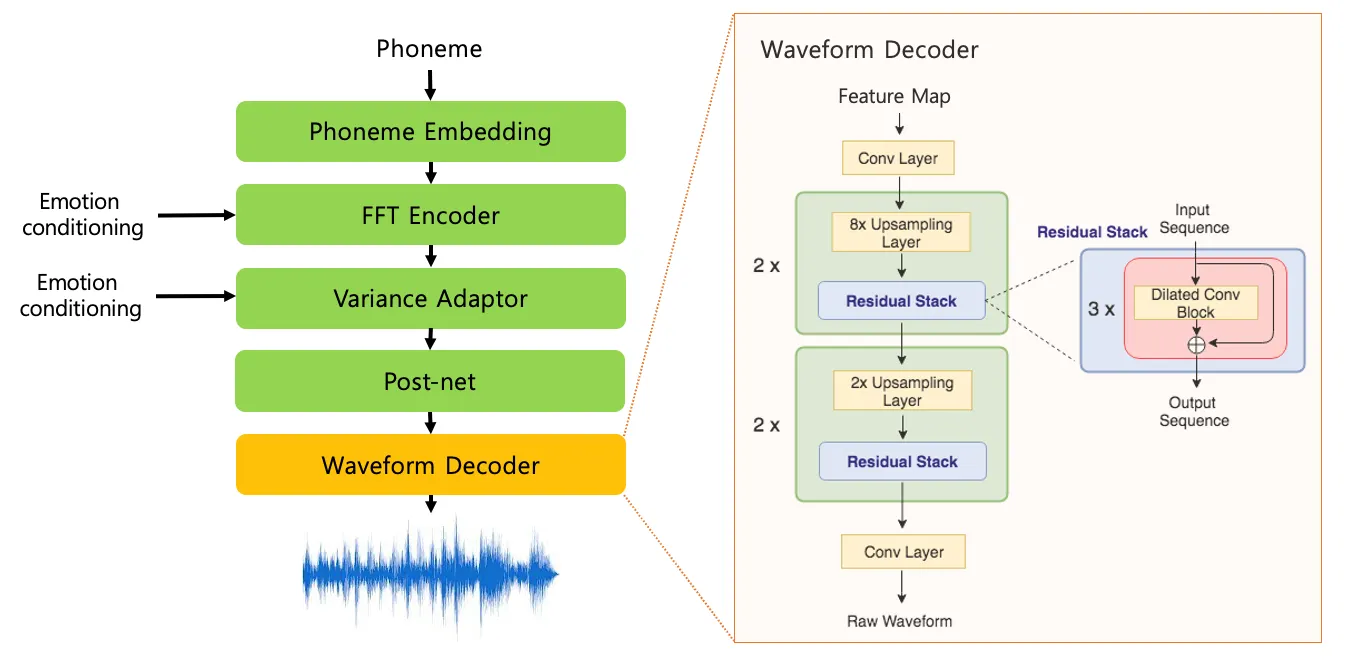
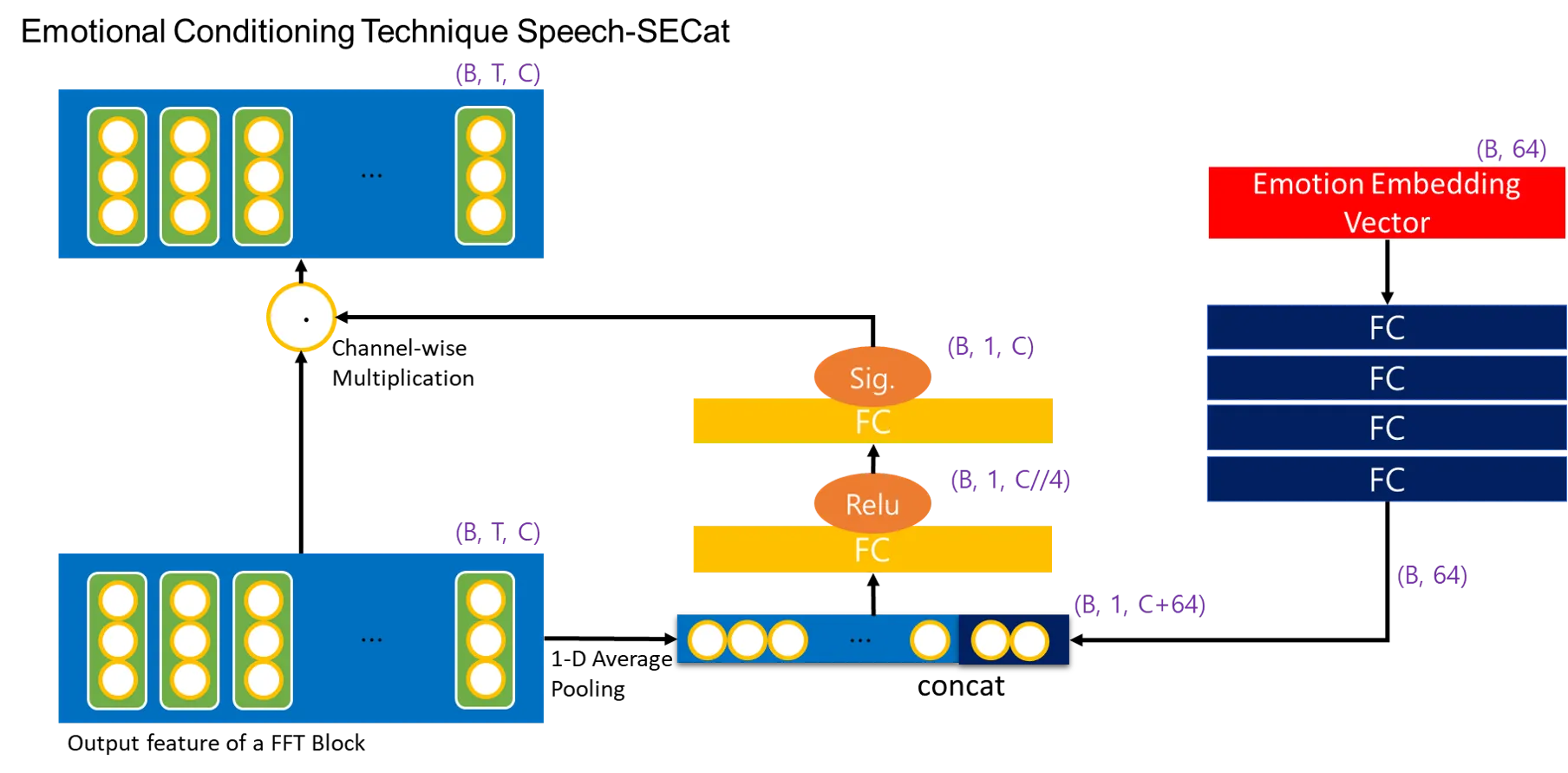
Unlike speech, singing voice 1) has a wide pitch range, 2) contains many notes with long duration, and 3) it is necessary to model a high sampling rate. We are trying to solve this problem based on the latest research on HiFiGAN, NSF, Parallel WaveGAN, etc. Applying the above studies focused on speech synthesis as it is causes several problems in high-quality singing modeling. (high, low pitch artifacts, glitch issue, etc.) Therefore, we are trying to develop a vocoder for singing voice that combines various GAN-based vocoders for high quality while taking the pitch robustness using the source excitation signal.
Singing Voice Synthesis
Speech Processing
Creative AI
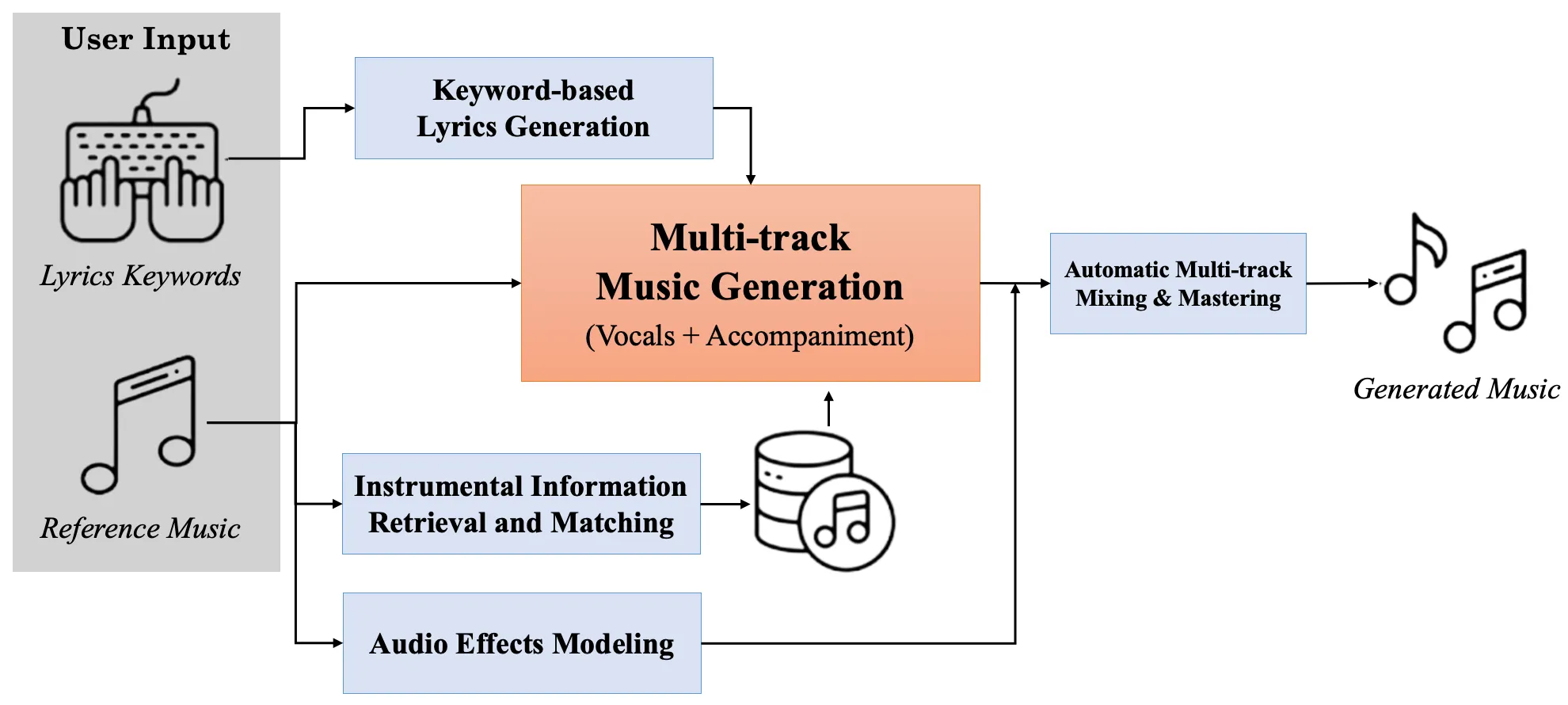
Music Production is the process of managing and overseeing the recording and production of music tracks. Intelligent Music Production (IMP) aims to introduce artificial intelligence into music production, allowing for automated processes while also reflecting the user's preferences. We believe that future studies on this topic will help artists and audio engineers simplify the complex process of traditional music production and provide them with a creative workflow.
Table of Contents
Our Interests Related to IMP
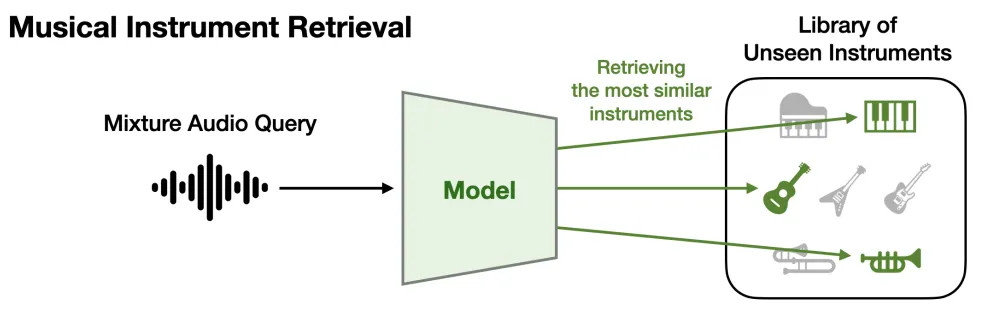
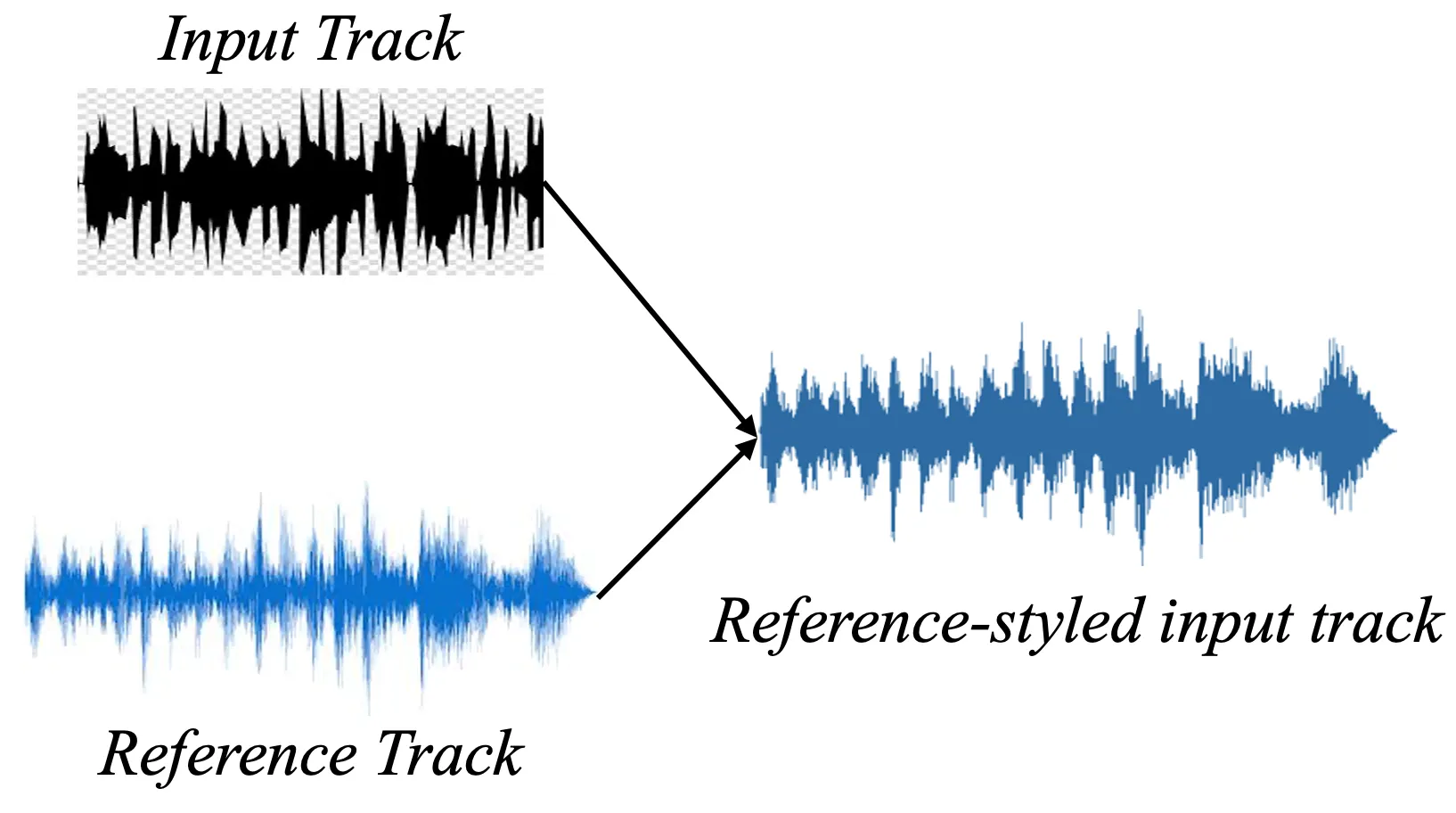
Music Post Production
Music production includes various sub-processes, from transforming each audio track with audio effects to mixing and mastering. In modern music production, most recorded tracks are digitally processed so that audio engineers seek a more convenient yet intricate digital tool for their workflow. IMP should therefore introduce
1.
straightforward procedures of the overall music production,
our publication: End-to-end Music Remastering System Using Self-supervised And Adversarial Training.
2.
new digital audio effects (DAFX) that previous approaches have not been capable of,
our publication: Reverb Conversion of Mixed Vocal Tracks Using an End-to-end Convolutional Deep Neural Network.
3.
and improving the availability and accessibility of existing complex DAFX modules.
our publication: Differentiable Artificial Reverberation.
Intelligent Music Production
Signal Processing
Music Production
