
Emotional Text-to-Speech (TTS)
Motivation
A typical speech synthesis model requires a vocoder to listen to what it sounds like through mel-spectrogram after creating mel-spectrogram in text. In recent years, the trend has shifted to studies that extract waveform from text end-to-end, rather than using pre-trained vocoder as an inference, to process speech synthesis potentially with more variance information of speech waveform and to inference directly rather than going through two steps of inference. Meanwhile, speech synthesis research that generates a speech waveform containing emotion information is in progress, and more robust performance can be demonstrated by reflecting emotion information in training. In this work, we propose a model that directly generates speech waveform containing emotion information more liveliness with our proposed technique, Speech-SECat, using conditional adversarial training.
Our Contribution
Non-Autoregressive TTS Model
End-to-end generation of waveform samples
Emotion-conditioned text-to-speech model
Method
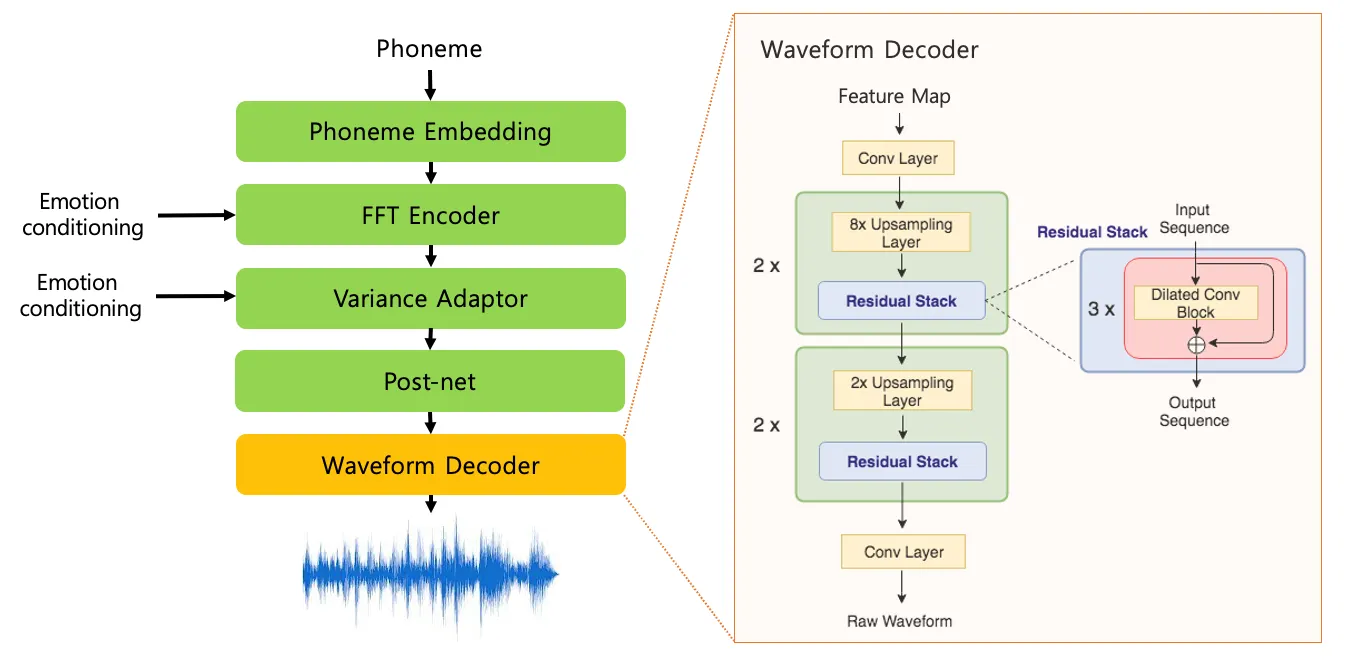
•
A scheme of the generator architecture, which consists of the FFT Encoder, variance adaptor, Post-Net, and waveform decoder.
◦
Emotion information is reflected by the Speech-SECat, which will explain in a next section, in the FFT encoder and variance adaptor while the generator is training.
◦
FFT encoder and variance adaptor output aligned feature maps by duration information
of input tokens.
◦
Post-Net reinforces the feature maps to represent more reasonable feature, and waveform decoder predicts and generates speech waveform from the feature maps of the Post-Net.
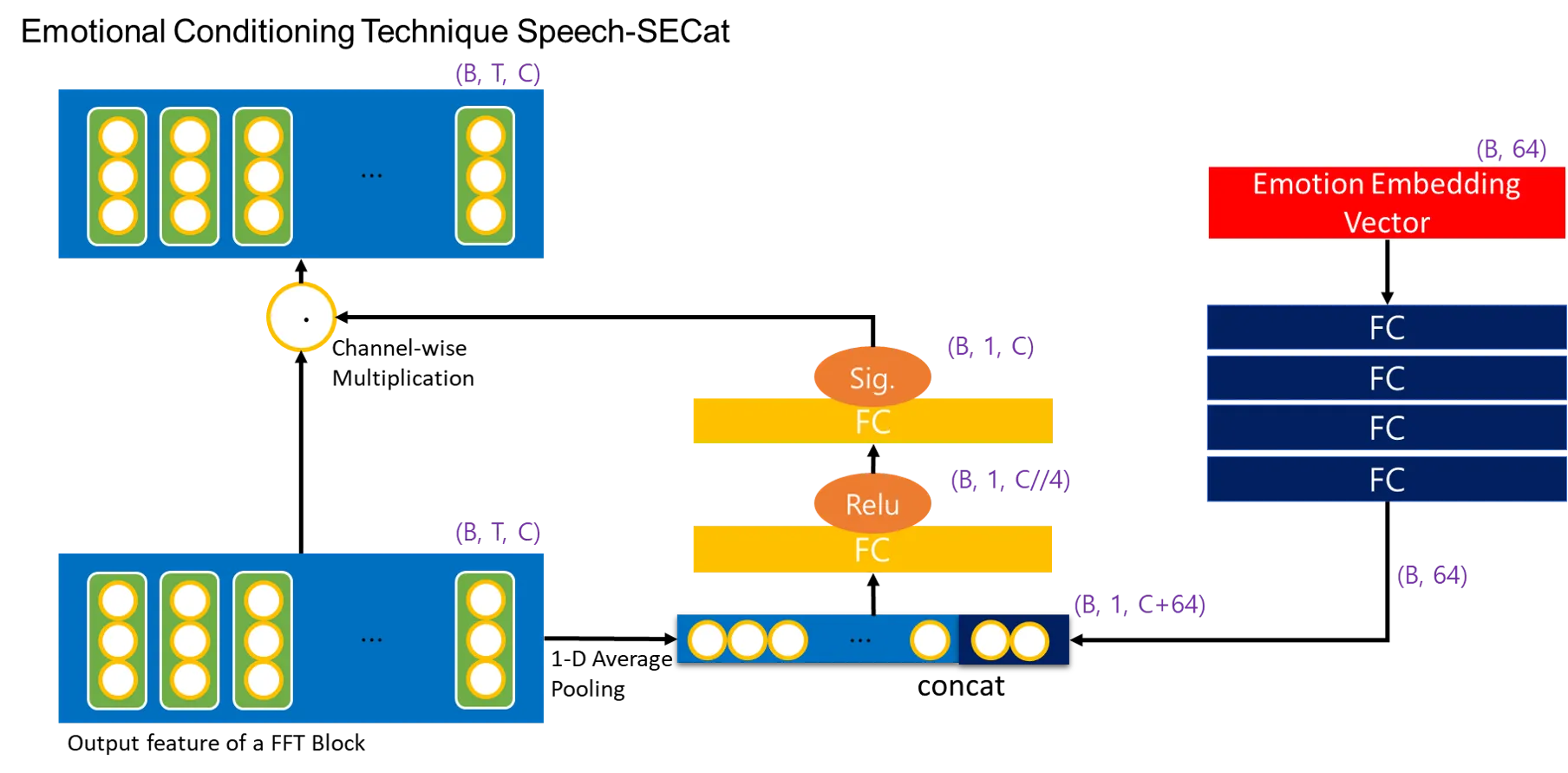
•
A scheme of the proposed Speech-SECat architecture. The architecture consists of three processes, squeeze, excitation, and concatenation.
◦
From output feature maps, squeeze process extracts spatial global average pooling, after which is concatenated with an emotion embedding vector.
◦
Proceeding Excitation process recalibrates the output feature maps adaptively, to multiple channel-wise importance weights to the output feature maps.
◦
Channel-wise importance weights is feed-forwarded by the two FC layers.
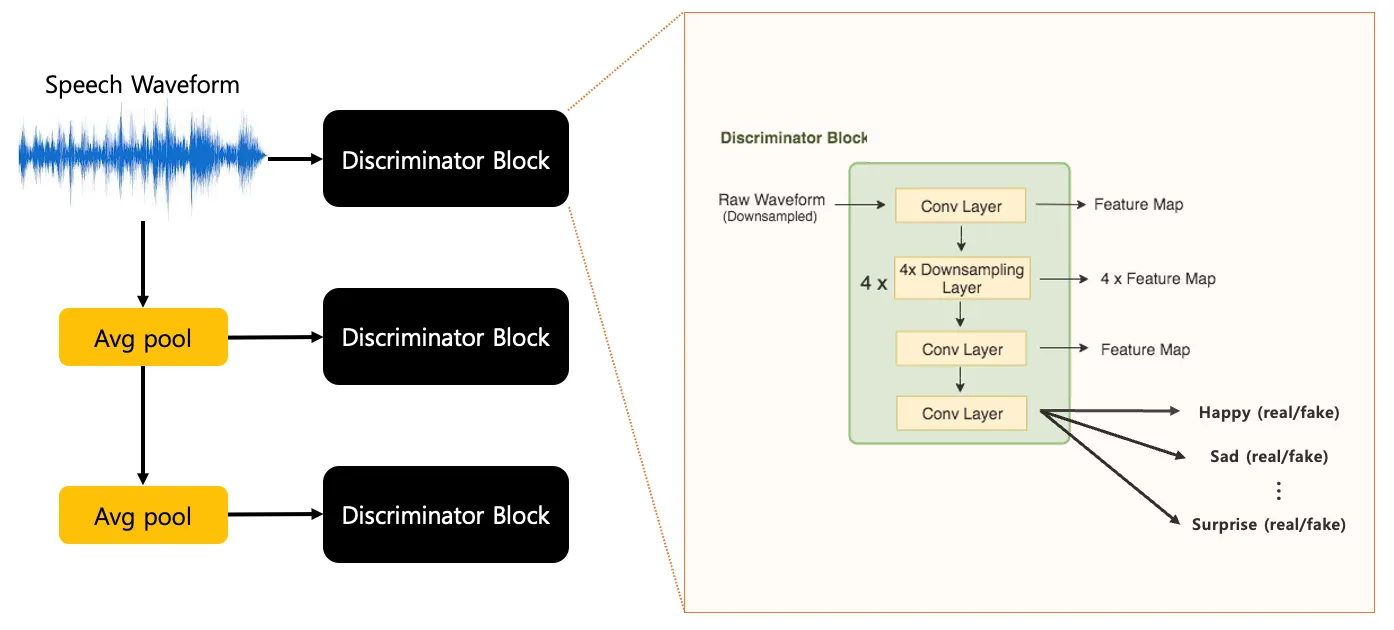
•
A scheme of the multi-task discriminator architecture modified the whole discriminator of MelGAN which has an inductive bias that each 3 of discriminator learns features for different frequency range.
◦
Each average pooling layer downsamples speech waveform by a factor of 2 and 4 respectively, and each discriminator block outputs 6 of different levels of feature maps hierarchically and final output for each emotion domains which is a probability distribution each given by the discriminator.