
1. Introduction
‘Dance generation’ is a task of music-based motion generation that uses a rule-base or deep learning model to make realistic dance motions. In the past, rule-based models were mainly used, but recently, with the development of deep learning techniques, methods using deep learning have become a trend. This task requires musical knowledge and an understanding of human motion, especially dance. To this end, we use a model that has learned the relationship between musical features and dance movements to generate dance motion suitable for music.
2. Research
Automatic Choreography Generation with Convolutional Encoder-decoder Network
2.1. Motivation
In general, when people dance, they dance to match the music. In fact, dance is closely related to music. Many elements of dance follow the temporal and spectral characteristics of music. Therefore, it is necessary to understand both music and dance in order to create a dance that matches the music. However, it is very difficult for ordinary people who do not know much about dance or music to create dance. Therefore, we propose an end-to-end dance generation model that generates appropriate dance from music without any understanding of dance or music.
2.2 Method
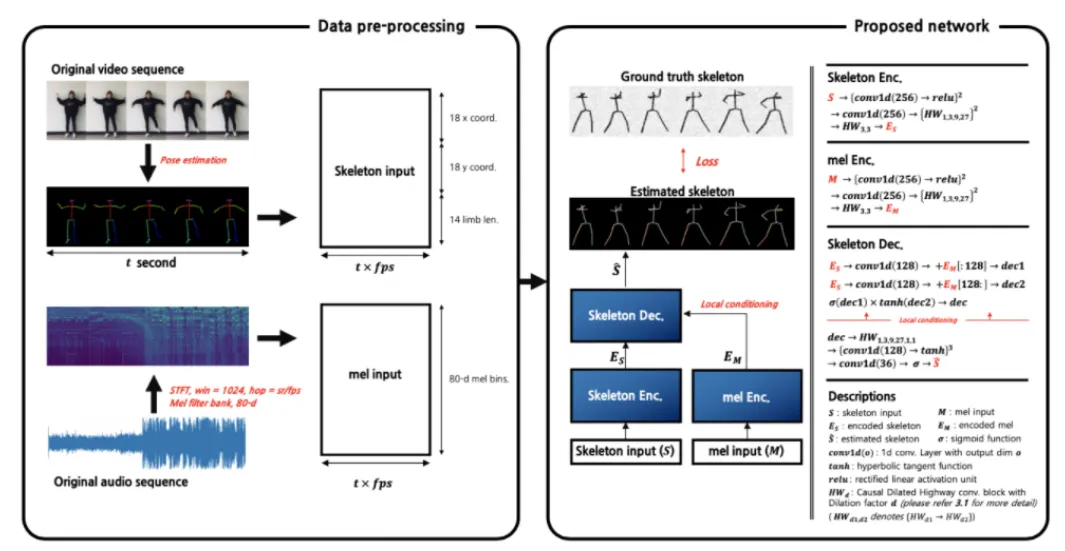
Figure 1. A schematic diagram of the music-driven dance generation system.
•
An end-to-end model that takes music as an input and generates dance that matches the music should be able to identify and learn the relationship between data from two completely different areas: music and dance. That is, it should be possible to learn the relationship between a musical feature sequence according to time and a dance motion sequence according to time. Therefore, our study is based on the seq2seq model that can perform multi-modal sequence to sequence transformation.
•
In particular, music and dance have an autoregressive characteristic in which a musical features or dance features at a certain point in time is determined by the musical features or dance features of a previous point in time. Therefore, using the autoregressive seq2seq model, it is possible to effectively learn the relationship between the temporal features of music and dance.
•
To predict data at a specific point in time based on past time series data, causal dilated convolution, which is widely used in speech synthesis, is used [1]. From this, it is possible to predict the motion at a specific point in time based on past motion features.
•
In addition, in order to generate dance motions suitable for the music given as input, the local conditioning methodology, which is mainly used in fields such as TTS, is applied to the network. Based on this, it is possible to complete the seq2seq model that creates a dance sequence that matches the sequence of music.
•
To extract time-series dance motion data from dance images, pose detection algorithm such as openpose is used [2]. In this way, pose information of a motion can be extracted in 2D or 3D from the image. The extracted time series pose information is used as dance motion data.
2.3. Result
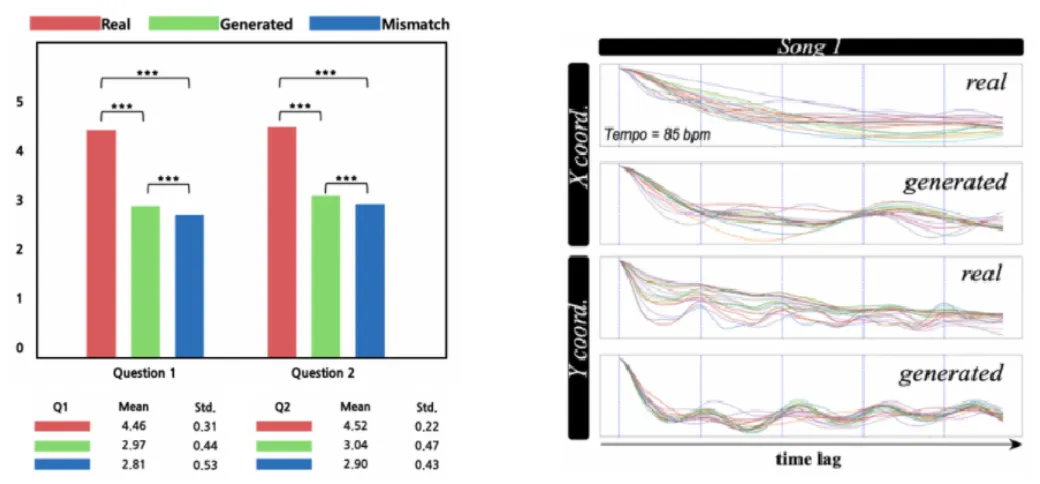
Figure 2. (Left) User study result. (Right) Autocorrelation result.
•
User study and periodicity of dance were used as evaluation methods. The user study asked two performance measures, the naturalness of the dance and the suitability of the dance and music. We compared performance measures for three groups(real dance, dance generated according to the given music, and randomly generated dance). Dance generated according to the music showed better results compared to randomly generated one for all measures.
•
Music and dance have many temporally significant characteristics, and if the dance is properly created for music, it can be assumed that the temporal characteristics of music and dance have similar patterns. Autocorrelation is a correlation with a given sequence itself, reflecting the periodic properties of the sequence. Therefore, by observing the autocorrelation of music and dance, it is possible to easily analyze the temporal patterns of the two sequences and evaluate their suitability. The picture on the right of Figure 2 shows the autocorrelation between music and dance. As a result, it can be seen that the autocorrelation tendencies of music and dance are very similar, and from this, it can be shown that dance suitable for music is generated.
2.4. References
[1] Aäron Van Den Oord, Sander Dieleman, Heiga Zen, Karen Simonyan, Oriol Vinyals, Alex Graves, Nal Kalchbrenner, Andrew W Senior, and Koray Kavukcuoglu. Wavenet: A generative model for raw audio. In SSW, page 125, 2016.
[2] Zhe Cao, Tomas Simon, Shih-En Wei, and Yaser Sheikh. Realtime multi-person 2d pose estimation using part affinity fields. In CVPR, 2017.
•
paper: Juheon Lee, Seohyun Kim, Kyogu Lee. “Automatic choreography generation with convolutional encoder-decoder network”, 20th International Society for Music Information Retrieval Conference, Delft, The Netherlands, 2019.
 shzkim@snu.ac.kr (Seohyun Kim, Ph.D. candidates)
shzkim@snu.ac.kr (Seohyun Kim, Ph.D. candidates)