


안녕하세요 
오늘은 많은 분들이 기다려오셨던 2022 NVIDIA GTC에서 Cochl이 발표한 세션(Link)을 톺아보려고 합니다. Cochl이 어떤 회사이고, 어떤 문제를 해결하고자 하는지 궁금하시다면 끝까지 함께 해주세요!
Cochl은 인간과 유사한 수준으로 우리 주변에서 발생하는 소리를 인식할 수 있는 Generalized Sound AI를 만드는 회사입니다. 여기서 말하는 Generalized Sound AI는 무엇이고 왜 필요할까요?
가령 인공 지능의 한 분야로 잘 알려져있는 Computer vision을 예시로 들어보겠습니다. Computer vision은 인공지능으로 하여금 인간 수준으로 특정 시각적 특징을 분석하고 이해하는 것을 목표로 하고 있습니다. OCR, Object detection, Object Tracking 등의 기술이 비전 분야를 대표합니다. 한편 시각 분야에 비해 청각 분야는 음악 분석이나 음성 인식 등 한정적인 영역에서만 많은 연구가 이뤄지고 있어 상대적으로 더 많은 연구가 필요합니다.
하지만 생각해보세요. 우리가 얼마나 다채로운 소리에 둘러쌓여 살고 있는지 말이죠! 노이즈 캔슬링 기능이 탑재된 이어폰을 끼지 않는 이상 우리는 소리로 가득한 세상에 살고있음을 느낄 수 있습니다. 음성은 그런 소리가 담고 있는 많은 정보 중 극히 일부일 뿐입니다. Cochl은 우리와 함께 살아숨쉬는 소리의 잠재력을 믿고, 소리가 우리에게 줄 수 있는 많은 정보를 통해 더 나은 삶을 살 수 있도록 ‘Generalized Sound AI’를 개발하고 있습니다.
왜 Generalized Sound AI가 필요할까요?
소리에 관한 연구는 딥러닝을 기반으로 진행하고 있습니다. 아래 두 가지 이유에서 말이죠.
1.
실제 상황에서 더 정확한 수행 능력과 낮은 오탐률을 보이기 위해서
2.
인간 수준의 소리 인식 능력을 갖추기 위해서
‘특정 소리만 구별해내면 되는거 쉬운 일 아니야?’ 라고 생각할 수도 있습니다만, 많은 인공지능 분야에서 그러하듯 소리 인식의 경우에도 마찬가지로 특정 소리를 구별해내기 위해 그 소리만 수집해 모델을 학습시키는 것이 끝이 아니라 유사한 위양성 소리도 함께 수집해 학습시켜야 합니다.
실제로 저희가 실제 총소리와 가짜 총소리를 구별해내는 유튜브 콘텐츠를 촬영해봤을 때도 많은 참가자들이 총소리와 폭죽 소리, 페트병 터뜨리는 소리를 헷갈려 했습니다. 결과적으로 세상에 있는 모든 소리를 인식하고, 이해할 수 있는 Generalized Sound AI 시스템이 갖춰져야만 우리가 원하는 특정 소리만을 구별해낼 수 있습니다.
만약 Generalized Sound AI가 없다면 세상에 존재하는 모든 디바이스와 녹음 환경을 고려해 사용할 때마다 새로운 시스템을 만들어 내야 하죠. 확장성이 낮고, 매번 우리를 귀찮게 하는 인공지능을 만드는 것이 과연 모든 인공지능을 연구하고 개발하는 사람들의 최종 목표일까요?
어떻게 Generalized Sound AI를 개발하나요?
소리 데이터의 경우 품질에 따라 다르지만, 일반적인 음질의 경우 초당 44,100개의 실수(숫자)로 이루어져 있어서 데이터 사이즈가 큰 편이며 모든 인공지능이 그러하듯 계속해서 최고의 성능을 향해 학습하고 개선하는 프로세스를 반복해야 합니다. 이 모든 과정을 빠르게 진행하는 것이 거친 기술 스타트업 생태계에서 살아남을 수 있는 방법 중 하나 입니다.
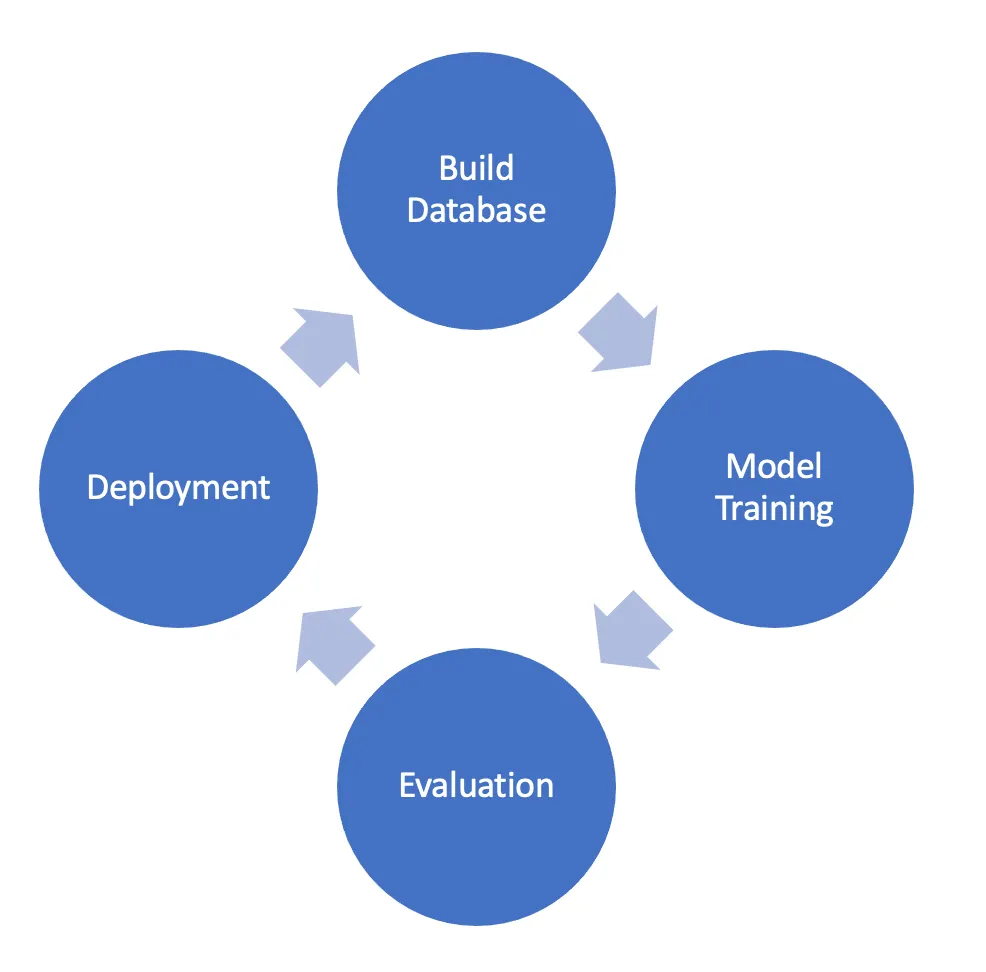
1.
Build Database ~ Model Training
Generalized Sound AI를 만들기 위해 다양한 데이터를 수집해야 하고, 저희는 가능한 모든 방법을 동원해서 수집하고 있습니다.
•
직접 녹음 (Manual recording)
•
크라우드 소싱 (Crowdsourcing)
•
고객 제공 데이터 (From our clients)
•
공공 / 사적 데이터 (Public / private data)
모든 데이터 수집 프로세스가 그러하듯 소리 데이터를 모을 때도 고려해야 하는 사항들이 있습니다.
•
데이터 녹음 환경의 다양성 (장비 / 날씨 / 형태 등)
•
법적, 사생활 침해 이슈
•
양보다는 질적으로 우수한 데이터 수집
예를 들어 사이렌 소리 하나를 수집하더라도 정차한 차에서 울리는 사이렌과 달리는 차에서 울리는 사이렌의 소리가 다르며, 국가별로도 사이렌 소리의 차이가 납니다. 또한 만약 차량 모델이나 사이렌 모델이 업데이트가 되면 또 달라지겠죠. 그렇기에 새로운 데이터를 수집하고, 데이터를 관리하고, 데이터끼리의 연관성을 실시간으로 파악할 수 있는 관리 툴이 필요합니다. Cochl에서는 그런 요구사항에 맞는 웹 기반의 오디오 라벨링 플랫폼을 직접 개발하여 데이터 관리 및 모델 학습을 진행하고 있습니다.
2.
Evaluation
세상에 완벽한 성능 평가 및 검증 방법이 존재한다면 영혼을 팔아서라도 알고 싶습니다. 하지만 이렇게 말하는 걸 보면 그런 방법은 없겠죠. 가장 많은 시간과 노력이 들어가는 부분입니다. 신뢰성 있는 모델을 만들기 위해 모델의 평가는 실제 상황에서 일어날 수 있는 대부분의 상황을 고려해 진행되어져야 합니다. 그리고 새로운 모델과 이전 모델의 성능을 비교하는 것도 빠질 수 없죠. 보통 Cochl에서 구모델과 신모델을 검증할 때는 아래의 요소들을 고려합니다.
•
만약 성능이 이전과 비교해서 떨어졌다면 이는 데이터의 문제일까? 혹은 모델의 문제일까?
•
새로운 데이터가 특이사항을 도출해내지 않았는가?
•
해당 모델이 가진 한계점은 무엇일까?
물론 무엇이 문제의 원인이 되었는지는 때로 찾기 어려울 때도 있습니다. 기술 분야에서 흔히 일어나는 일이지만, 무엇이 문제일지 모를 때는 모든 방법을 동원해서 이 잡듯이 뒤져봐야죠. 그럼 결국엔 발견할 수 있습니다. 오탐의 원인을 찾기 위한 방법을 구상해내는 것도 많은 창의력을 동원하는 일입니다. 하지만 발견해냈을 때의 짜릿함은 모두가 아실거예요.
3.
Deploy
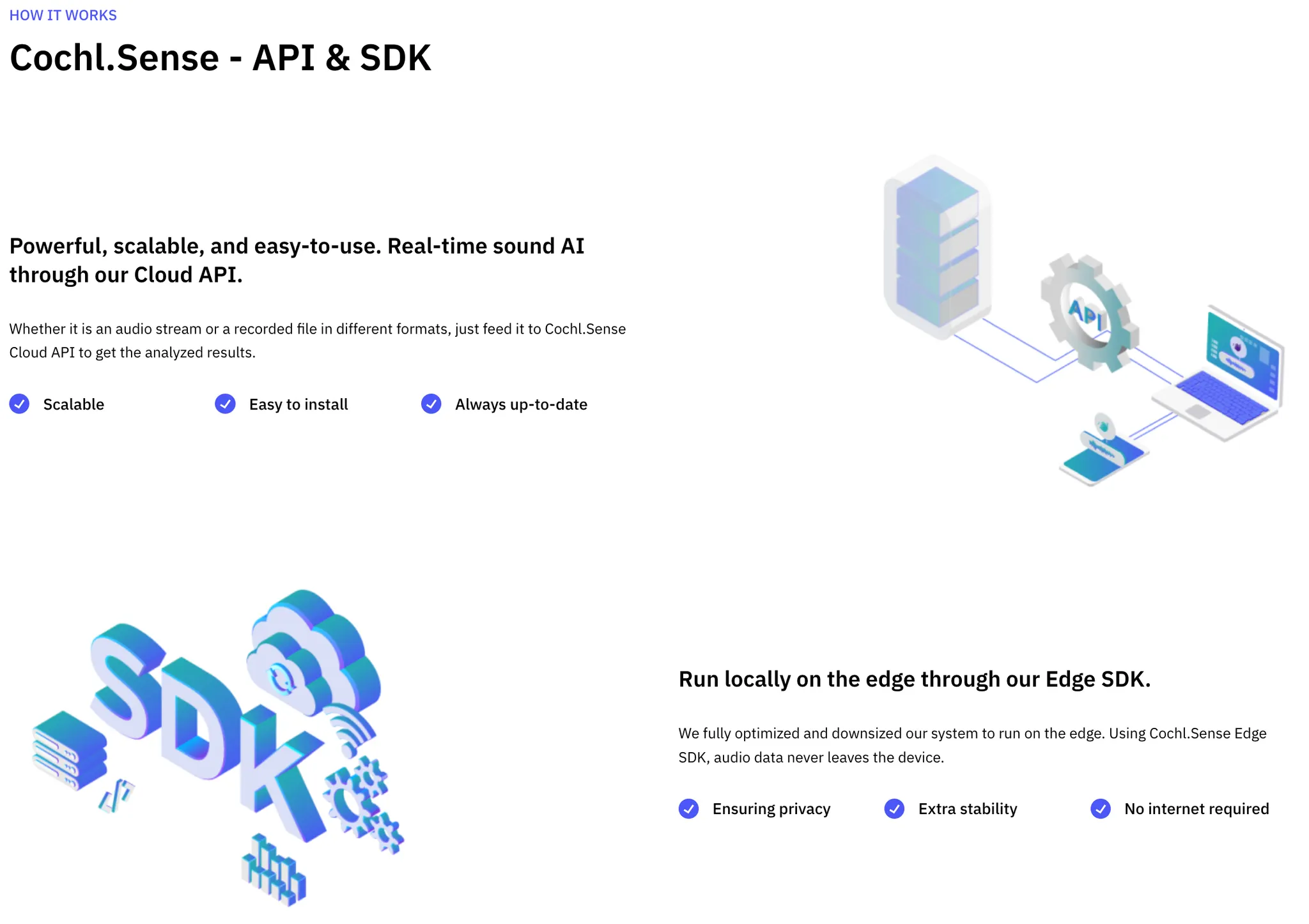
Cochl의 Sound AI 솔루션은 2가지 - API, SDK- 형태로 배포됩니다. 각각은 아래와 같은 특징이 있습니다.
•
Cloud API
◦
클라우드 형태로 제공
◦
확장성 있는 시스템
◦
최신 기술 제공
◦
별도 디바이스가 필요하지 않음
•
Edge SDK
◦
기기별 최적화 가능
◦
프라이버시 이슈 최소화
◦
모든 주요 플랫폼 지원
◦
별도 인터넷 연결이 필요하지 않음
현재 Cochl.Sense를 통해 약 20가지 클래스의 소리를 판별할 수 있으며, Dashboard를 통해 주요 지표를 실시간 확인할 수 있습니다. Cochl의 Generalized Sound AI 시스템을 통해 1. API / SDK 프로덕트를 통한 소리 데이터 수집 및 탐지 2. Dashboard를 통한 사후 조치를 가능하게 하여 소리 데이터와 관련된 모든 분석을 한 번에 진행할 수 있습니다.
우리의 최종 목표는?
Cochl의 목표는 결과적으로 하나의 통합된 Sound AI 시스템을 만드는 것입니다. 다만 현재로써는 각 소리의 특성이 너무 다른 경우 각각의 모델을 만드는 것이 더 나은 결과를 보이는 것을 확인했습니다. 딥러닝 모델을 통해 각 모델을 통합하는 것이 최종 목표지만 현 단계에서는 각 카테고리 별로 시스템을 잘 분화해 더 정확하고, 효율적인 시스템을 만드는 것을 우선으로 하고 있습니다.
Cochl이 집중하고 있는 Sound AI 기술은 near - ultimate Sound AI / Music Analysis / Speech Analysis로 크게 나눌 수 있으며 Cochl.Labs에서 Cochl의 최신 기술을 직접 경험할 수 있습니다.
소리 인식 인공지능 회사는 처음이신가요? 모쪼록 오늘의 세션을 통해 Cochl이 어떤 회사인지, 어떤 목표를 가지고 있는지 잘 설명해드렸길 바랍니다. Cochl과 저희가 보유한 기술과 관련해 궁금한 부분이 있으시다면 언제든지 편하게 contact@cochl.ai로 연락 부탁드립니다! 재미있는 질문과 커피챗과 대화는 언제나 환영입니다