


Cochl은 음성인식을 넘어 우리 주변에 있는 다양한 소리를 모두 알아들을 수 있는 Sound AI 기술을 만드는 회사입니다. 인공지능이 사람처럼 자연스러운 청각 인지능력을 가질 수 있도록 하고, 이를 통해 사람들이 안전하고 자동화된, 그리고 편리하고 개인화된 일상 생활을 누릴 수 있도록 만들어 나가고 있습니다. 다양한 AI 모델들이 매일 업데이트 되는 요즘 시대에 Cochl은 어떻게 AI 모델을 고도화하고 있을까요?
AI 모델을 고도화하기 위해서는 다양한 방법들이 존재합니다. 모델 설계 시의 구조나 학습 방법을 개선하는 등의 기술 개발뿐만 아니라, 양질의 데이터셋을 확보하는 것 역시 모델의 성능에 결정적인 영향을 미친다는 점, 알고 계셨나요? 흔치 않은 소리 데이터를 다루는 Cochl에서 어떻게 소리 데이터를 수집하고, 레이블 해서 고성능의 AI 모델을 만들고 있는지 소개해 드립니다.


소리 데이터 수집의 판단 기준은?
양질의 소리 데이터셋을 정의하고 구축 계획을 세우는 것은 어려운 일입니다. 모델의 목적이나 사용될 상황에 따라 다양한 품질 기준이 요구되기도 하고, 심지어 이러한 기준은 시간이 지나감에 따라 바뀔 수도 있고, 더욱 상향되기도 합니다.
위 문제를 해결하기 위해 Cochl에서는 시장 조사, 최신 연구 동향 파악, 전문가 감수 등의 다양한 방법을 데이터 수집 단계에 활용하고 있습니다. 그중 모델의 지속적인 개선을 위해 이전 버전 모델의 성능 평가 결과를 바탕으로 다음 데이터 수집 계획을 수립하는 Data-driven 방식을 조금 더 자세히 설명해 드릴게요.
Data-driven 방식은 지난 모델의 성능 평가 결과를 보며 특별히 인식 성능이 떨어지는 사용 환경이 있었는지, 비슷한 소리 특성이 있어 모델이 혼동하기 쉬운 종류의 소리가 있는지를 파악한 뒤 이를 보완하기 위한 데이터를 추가로 수집하는 방식입니다.

예를 들어, 고양이 울음소리를 한번 떠올려 보세요. ‘야옹’하는 명확한 소리가 떠오르지 않으시나요? 이러한 소리는 고양이만의 독특한 특징을 가지고 있다고 생각할 수 있습니다. 그러나 저희가 이러한 가정을 바탕으로 데이터를 수집하고 학습한 모델의 성능을 분석해 보았을 때, 일부 고양이 울음소리의 경우 아기가 울거나 칭얼거리는 소리와 매우 유사해 혼동이 일어나는 경우가 있었습니다.
물론 두 소리가 완전히 같은 특징을 가진 것은 아니지만, 그 시점에 저희가 확보한 데이터는 그러한 미묘한 차이를 구분하는 소리를 포함하지 못했던 것이기 때문입니다. 이러한 발견 후 Cochl에서는 아기 우는 소리와 유사한 고양이 소리, 고양이 소리와 유사한 아기 우는 소리를 추가로 수집해 학습 데이터로 포함했으며, 그 후 개발된 모델에서는 두 소리 간의 혼동이 매우 감소했습니다. ( 더 읽어보기: 서비스로 사용 가능한 모델이란? - 위양성 (false-positive) 데이터 고려하기!)
더 읽어보기: 서비스로 사용 가능한 모델이란? - 위양성 (false-positive) 데이터 고려하기!)어떻게 소리 데이터를 수집할 것인가?
어떤 소리를 인식하는 모델을 개발하려고 할 때, 소리의 범위를 정의하는 것은 매우 복잡한 문제입니다. “야옹”만이 고양이 소리가 아니라, “냥” 혹은 “먀오”하는 소리도 고양이 소리인 것처럼요. 소리 자체의 정의가 모호하거나 주관적인 경우는 물론이고, 너무 작게 들리거나 잡음에 묻히는 등 주변 환경에 영향을 받을 수도 있습니다. 따라서 수집 단계에서부터 어떤 소리인지 명확하게 정의하고, 어느 정도 범위까지 데이터셋에 포함할 것인지를 고려하는 것이 필요합니다.

실수로 수도꼭지를 틀어두고 집을 비웠을 때, 물이 흐르는 소리를 인식해 알림을 보내주는 서비스를 위한 모델을 개발한다고 가정해볼게요. 이 경우, 수집하고자 하는 ‘물 흐르는 소리’의 범위는 가정 내 다양한 수도 소리 - 세면대, 샤워기, 싱크대, 정수기 - 등이 포함될 것이고, 시냇물이나 하수도와 같은 소리는 제외될 것입니다. 또한 이런 소리가 발생하는 환경의 특징에 따라 발생하는 잡음들 - 화장실 환풍기 소리, 에어컨 소리 - 또한 고려돼야 합니다. Cochl은 수집 과정에서 위와 같은 고려 사항들을 충분히 고민한 후 실제 환경과 가능한 유사한 데이터를 수집해 품질을 극대화하고 있습니다.
수집된 소리 데이터의 레이블링은?
이제 고성능의 AI 모델을 만들기 위한 밑 준비는 모두 마쳤습니다. 남은 건 이를 어떻게 레이블링 하느냐로, 이 레이블링 과정에 따라 모델의 정확도가 달라집니다.
우선 데이터 레이블링이란 무엇일까요? 이는 모델이 데이터를 학습하기 위한 정답지를 만드는 과정을 말합니다. 어떤 소리들이 우리가 인식하고자 하는 소리 (고양이 소리, 아기 울음소리, 수돗물 소리)인지, 어떤 소리들이 그 소리들이 아닌지를 사람이 직접 기록하고, 모델은 이를 토대로 이후 어떤 소리가 났을 때 위 소리 종류로 인식해야 할 지를 학습합니다. Cochl은 자체적으로 개발하는 소리 데이터 특화 레이블링 플랫폼과 함께 오랜 시간 누적된 경험을 토대로 최적의 레이블링 방법을 활용하고 있으며, 특히나 아래 2가지 방식을 중점적으로 사용합니다.
1. 다양하고 풍부한 소리 종류 레이블링
홈페이지에서 확인할 수 있듯 Cochl.Sense 서비스에서 제공하는 클래스는 총 104개입니다. 그러나 이는 Cochl 내부적으로 데이터를 수집하고 학습하는 클래스 중 일부에 지나지 않으며, 실제로는 천 개 내외의 클래스를 함께 고려하고 있고 이는 지금도 계속해서 늘어나고 있습니다. 그렇게 많은 클래스가 왜 필요할까요?
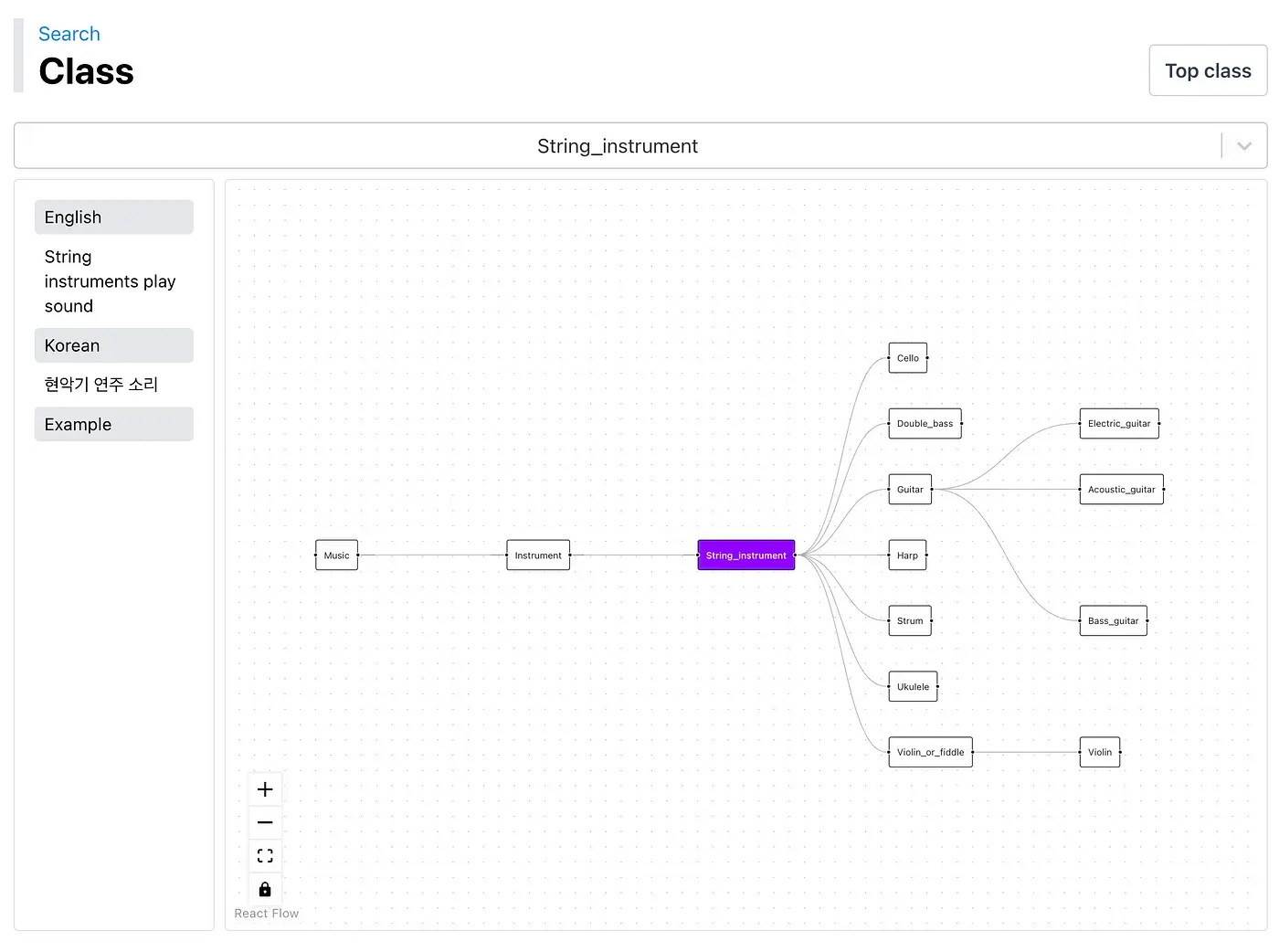
크게 두 가지 이유가 있습니다. 우선 어떤 소리에 대한 데이터를 확보할 때, 해당 소리와 유사하지만 다른 소리 데이터를 함께 수집해 모델의 오검출을 최소화하기 위함입니다. 두번째로, 각 클래스를 모두 개별적으로 처리하는 대신 각각의 의미적 관계를 표현하기 위함입니다. 클래식 기타와 전자 기타는 모두 기타 범주로 묶일 수 있고, 기타와 피아노는 모두 악기 범주로 묶일 수 있는 것 처럼요. 이러한 클래스간의 관계를 통해 레이블링을 진행하면 더 풍부하게 정보를 활용할 수 있습니다.
2. 최대한 사람과 가깝게 레이블링
앞서 밝혔듯, Cochl의 목표는 사람처럼 들을 수 있는 능력을 보유한 Sound AI를 개발하는 것입니다. 하지만 사람마다 같은 소리를 들어도 다른 소리로 인식할 수 있습니다. 마치 한 때 사람들의 호기심을 자극했던 Yanny vs Laurel 논쟁처럼요.
그렇기에 한 파일당 적어도 2명 이상이 레이블링을 진행하고, 1명 이상이 해당 레이블을 검수하여 최대한 다양한 의견을 반영할 수 있도록 하였습니다. 모델 테스트의 경우에도 모델이 사람이 듣는 것과 같게 듣고 있는지 사람이 검수하는 과정을 포함하여 정확도를 높이기 위해 큰 노력을 기울이고 있습니다.
앞으로 Cochl이 더 나은 AI 모델을 만들기 위해 할 것들
지금까지 Cochl이 양질의 소리 데이터를 수집하기 위해 고려하는 것들에 대해 이야기를 나눠봤습니다. 그렇다면 소리 인식 모델이 지금보다도 더 높은 성능을 보이기 위해 데이터 수집 측면에서는 어떤 점들이 개선될 수 있을까요?
모델의 학습을 위해 확보한 데이터양은 계속해서 증가하는데, 이 모든 과정을 사람이 직접 수행하게 되면 어떤 일이 발생할까요? 더 오랜 시간이 걸리는 것은 물론이고, 소수의 참여자가 똑같은 작업을 반복적으로 수행하면서 생기는 편향을 피하기는 어려울 수 있습니다.
따라서 이런 부분을 보완하기 위하여 데이터 수집 과정에서 데이터셋 구축 계획과 실행, 레이블링 과정을 자동화하여 Cochl에서는 더 빠르고 정밀한 데이터셋 구축을 시도하고 있습니다.
계속해서 발전하는 저희의 모습을 지켜봐 주시길 부탁드리며, Cochl 혹은 Cochl이 다루는 기술에 대해서 궁금하신 분들은 언제나 편하게 contact@cochl.ai 로 연락 부탁드립니다