

Pop2Piano is the task of generating a piano arrangement from a given pop music audio.
1. Introduction
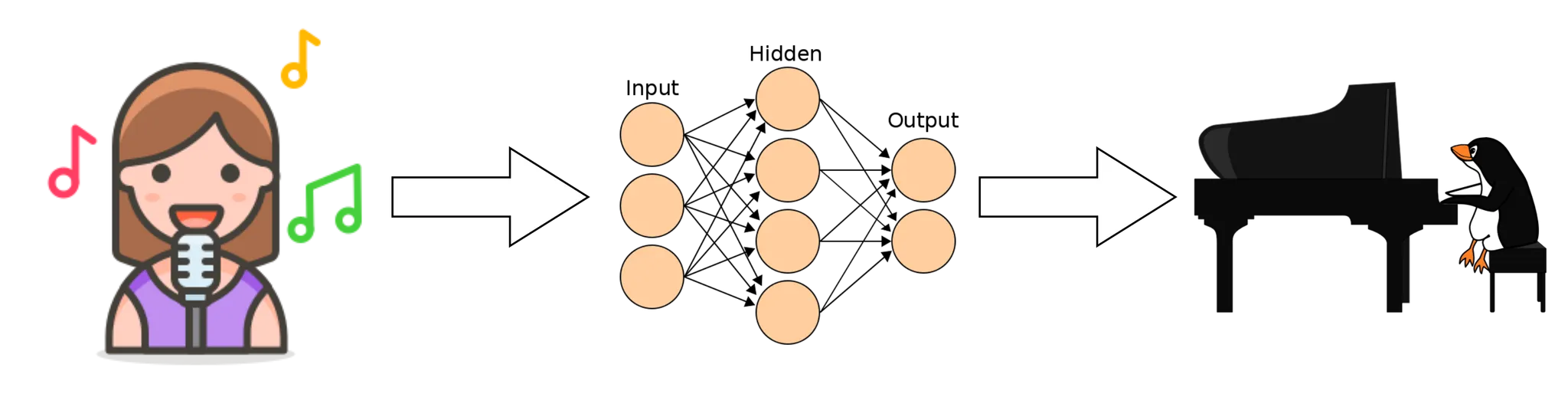
Arranging pop music into piano music is something that only music experts can do. This arrangement of music is used for hobbies, education, and business purposes. The MIR field has developed a lot using deep learning technology. Deep learning can analyze the genre or mood of pop music (Music Tagging, Music Mood Estimation) [1] and automatically generate pop MIDI (MIDI Generation) [2]. In addition, there has been a lot of progress in estimating piano MIDI from raw audio(Music Transcription). However, as far as we know, there was no work of arranging pop music directly into piano performance using deep learning. We call this work Pop2Piano.
Pop2Piano is the work of generating piano arrangements conditioned on pop music. Through the automated data collection/purification process, we created a dataset with thousands of pop music and piano arrangement MIDI pairs.
We are conducting research to automatically arrange pop music on the piano by learning patterns of these data using deep learning. Below is a sample of the data. (It is optimized for stereo audio. One side is the piano and the other side is the original. )
(KPOP Male Group) BTS - Butter
(KPOP Female Solo) Rosé - On the Ground
(POP Mixed Vocal) Ryan Gosling & Emma Stone - City of stars
2. Methods
Generating piano arrangement usually require consistent beat and chord progression from a long-term perspective. At the same time, it should be able to capture variable features such as vocal melody in the short term. The best neural network for these tasks is a sequence-to-sequence transformer model with an encoder-decoder structure. The most difficult thing in this work is to model the long-term dependency of music.
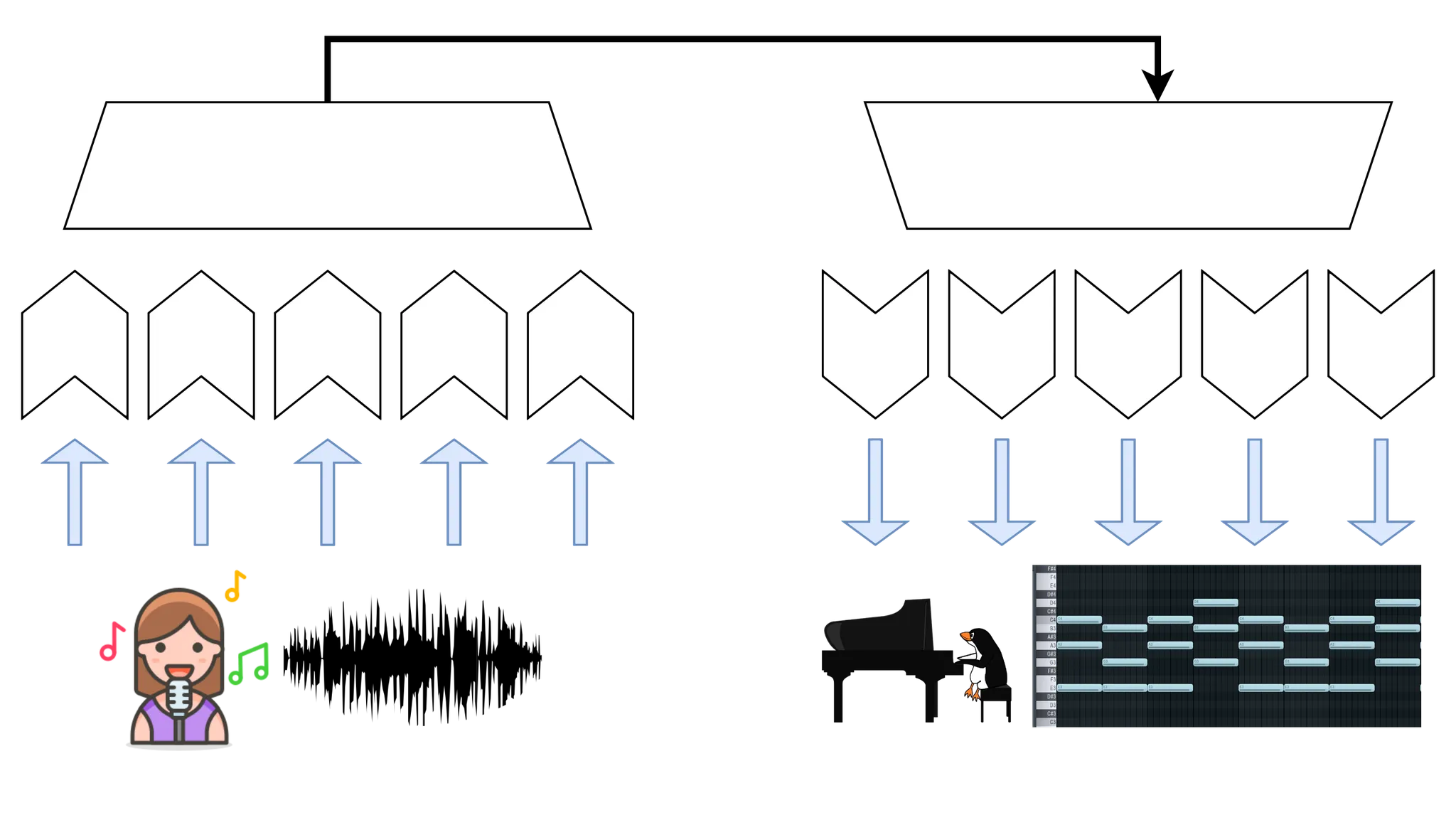
However, the transformer model requires a very high memory consumption when the sequence is long, so it is difficult to directly use the transformer model for music audio and midi output. There are many ways to solve these problems.
1.
Using a transformer model with linear memory complexity.
2.
Two features: a feature extractor with a wide receptive field and a feature extractor with a narrow receptive field to model the long-term consistency and short-term accuracy of the arrangement.
We are conducting an experiment by applying these methods, and below is the sample results.
(This is the result of cherry picking, and we're working on it to make it work robust in general.)
Sample 1
Sample 2
3. Why Pop2Piano is hard?
Music Transcription is the most similar task to Pop2Piano in that the form of input/output is the conversion of raw music audio to MIDI. However, Pop2Piano has the following differences compared to Music Transcription.
1.
There is no ground-truth label. Piano arrangements can exist in various forms even with the same audio input.
2.
It is difficult to collect a dataset that guarantees an accurate time alignment between input and output. As shown in data samples above, the time alignment between input and output is not accurate. (For example, MAESTRO [6], a piano audio-MIDI dataset, has a very accurate time error within 3 ms. This is because it was collected using a special electrical piano device. However, Pop2Piano datasets cannot do so. )
3.
It is difficult to collect data. Originally, it is difficult to obtain music data in the MIR field, and it is more difficult to collect piano arrangements and corresponding pop music. Piano arrangements collected online are often modified by the arranger. This is the noise of data, making it difficult to obtain high-quality data in large quantities.
Pop2Piano can be said to be similar to Music Generation. These include studies that generate MIDI sequence in MIDI domain [2, 7, 8], and studies that generate music in raw music audio [9]. However, these tasks differ in the form and purpose of input/output from Pop2Piano.
However, as far as we know, there have been few studies that generates piano arrangements conditioned on raw music audio..
4. Conclusion
Our research still has a long way to go, but I hope we can meet at the conference with good results soon.
5. References
[1] Jongpil Lee, Jiyoung Park, Keunhyoung Luke Kim, & Juhan Nam. (2017). Sample-level Deep Convolutional Neural Networks for Music Auto-tagging Using Raw Waveforms.
[2] Yu-Siang Huang, & Yi-Hsuan Yang. (2020). Pop Music Transformer: Beat-based Modeling and Generation of Expressive Pop Piano Compositions.
[3] Curtis Hawthorne, Erich Elsen, Jialin Song, Adam Roberts, Ian Simon, Colin Raffel, Jesse Engel, Sageev Oore, & Douglas Eck. (2018). Onsets and Frames: Dual-Objective Piano Transcription.
[4] Jong Wook Kim, & Juan Pablo Bello. (2019). Adversarial Learning for Improved Onsets and Frames Music Transcription.
[5] Curtis Hawthorne, Ian Simon, Rigel Swavely, Ethan Manilow, & Jesse Engel. (2021). Sequence-to-Sequence Piano Transcription with Transformers.
[6] Curtis Hawthorne, Andriy Stasyuk, Adam Roberts, Ian Simon, Cheng-Zhi Anna Huang, Sander Dieleman, Erich Elsen, Jesse Engel, & Douglas Eck. (2019). Enabling Factorized Piano Music Modeling and Generation with the MAESTRO Dataset.
[7] Hao-Min Liu, & Yi-Hsuan Yang. (2018). Lead Sheet Generation and Arrangement by Conditional Generative Adversarial Network.
[8] Muhamed, A., Li, L., Shi, X., Yaddanapudi, S., Chi, W., Jackson, D., Suresh, R., Lipton, Z., & Smola, A. (2021). Symbolic Music Generation with Transformer-GANs.
[9] Prafulla Dhariwal, Heewoo Jun, Christine Payne, Jong Wook Kim, Alec Radford, & Ilya Sutskever. (2020). Jukebox: A Generative Model for Music.