
1. Introduction
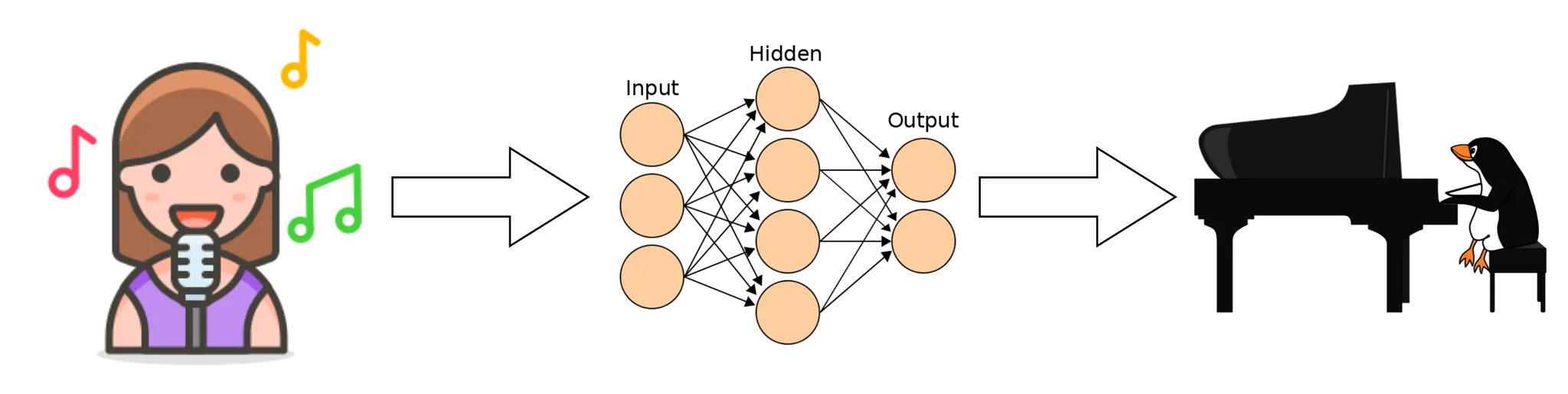
팝 음악을 피아노 버전으로 편곡하는 것은 전문가가 할 수 있는 일입니다. 사람들은 이렇게 편곡된 음악을 취미, 교육, 사업적인 용도로 사용하고 있습니다. MIR 분야는 딥러닝 기술을 이용하여 함께 많이 발전해왔습니다. 딥러닝을 이용하여 팝 음악의 장르와 분위기를 분석할 수 있고(Music Tagging, Music Mood Estimation) [1] , 또는 팝 피아노 MIDI를 자동으로 생성(MIDI Generation) [2] 해내기도 했습니다. 또한 피아노 오디오를 자동으로 MIDI로 추정해내는 작업(Music Transcription) [3, 4, 5] 도 많은 발전이 있었습니다. 그러나 딥 러닝을 이용하여 팝 음악을 직접 피아노 연주로 편곡하는 작업은 우리가 아는 한 없었습니다.
POP2PIANO는 팝 음악을 조건부로 그에 맞는 피아노 편곡을 생성하는 작업입니다. 우리는 자동화된 데이터 수집/정제 과정을 통해 수 천 곡의 팝 음악과 그에 맞는 피아노 편곡 MIDI 쌍을 갖는 데이터셋을 만들었습니다.
우리는 딥러닝을 이용하여 이러한 데이터로부터 패턴을 학습하여 팝 음악을 자동으로 피아노 버전으로 편곡하는 작업을 하고 있습니다. 아래는 데이터의 샘플입니다. (스테레오 오디오에 최적화되어있습니다.)
(KPOP Male Group) BTS - Butter
(KPOP Female Solo) Rosé - On the Ground
(POP Mixed Vocal) Ryan Gosling & Emma Stone - City of stars
2. Methods
피아노 편곡은 대개 장기적인 관점에서 일관된 박자와 코드 진행이 있어야 합니다. 그러면서도 단기적으로는 보컬 멜로디와 같은 가변적인 연주를 함께 포착할 수 있어야 합니다. 이러한 작업에 가장 적합한 뉴럴 네트워크는 인코더-디코더 구조를 갖는 sequence-to-sequence 트랜스포머 모델입니다. 이러한 작업에서 가장 어려운 점은 음악의 Long-term dependency를 모델링하는 것입니다.
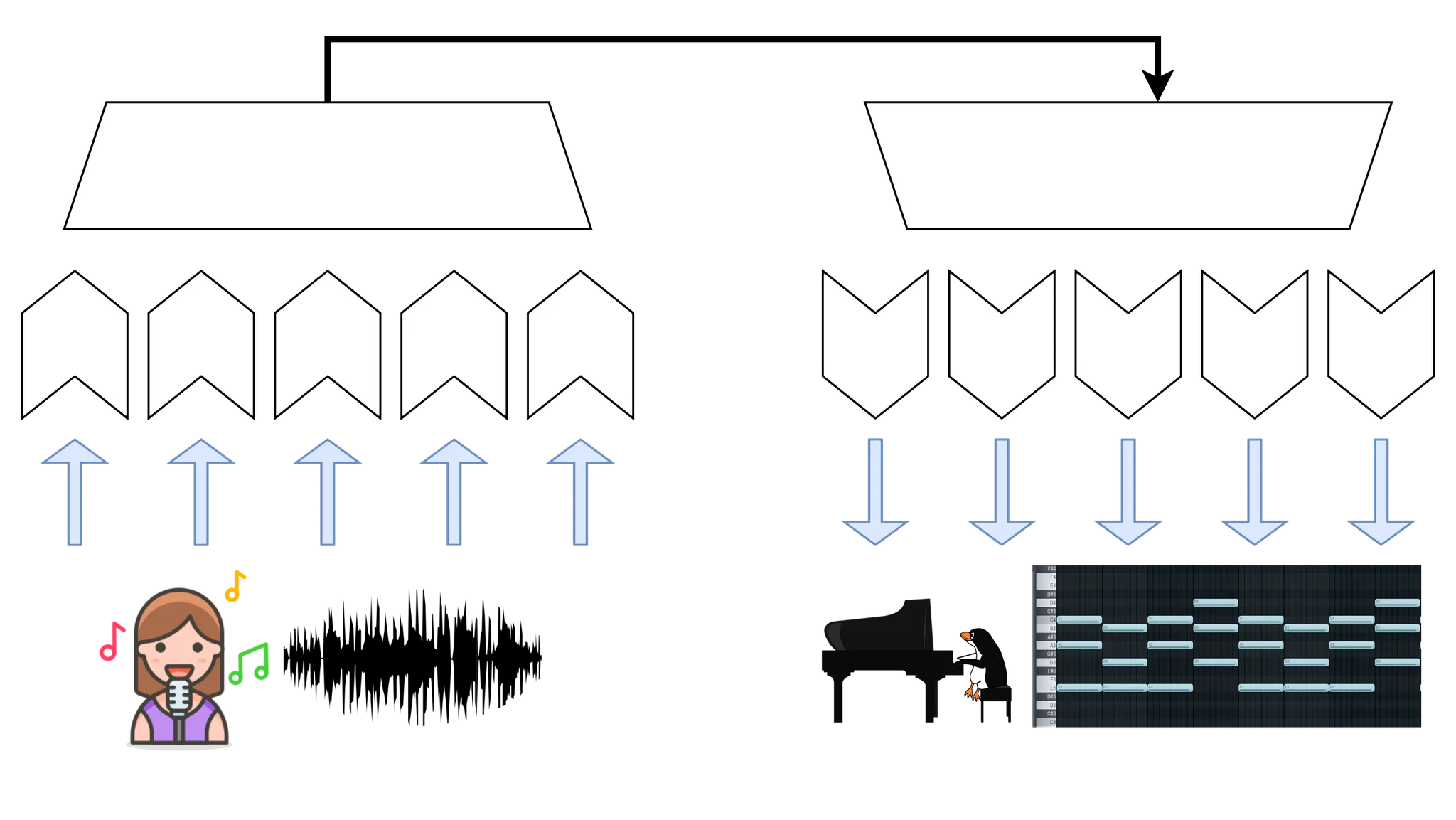
그러나 트랜스포머 모델은 시퀀스가 길면 메모리 부담이 매우 크므로, 음악 오디오 및 midi 입출력에 트랜스포머 모델을 직접적으로 사용하는 것은 어렵습니다. 이러한 문제를 해결하고자 여러 가지 방법을 사용할 수 있습니다.
1.
sequence 길이에 대한 Memory complexity를 Linear하게 줄인 트랜스포머 모델을 사용하여 더 긴 sequence에 대한 모델링
2.
두 가지 feature : 넓은 receptive field를 갖는 feature extractor와 좁은 receptive field를 갖는 feature extractor를 사용하여 편곡의 장기적 일관성과 단기적 정확성을 모델링
이러한 방법들을 적용하며 실험을 진행하고 있으며, 아래는 샘플 결과입니다.
(체리피킹 된 결과이며, 더 일반적인 환경에서 잘 동작할 수 있도록 하기 위해 연구하고 있습니다.)
Sample 1
Sample 2
3. Why Pop2Piano is hard?
Music Transcription은 입출력의 형태가 Raw Music Audio를 MIDI로 변환하는 작업이라는 점에서 Pop2Piano와 가장 비슷한 작업입니다. 그러나 Pop2Piano는 Music Transcription과 비교하여 아래와 같은 차이점이 있습니다.
1.
Ground-Truth Label이 없습니다. 피아노 편곡은 같은 오디오 입력일지라도 다양한 형태로 존재할 수 있습니다.
2.
입력과 출력 사이의 정확한 시간 정렬(Time Alignment)이 보장된 데이터셋을 구하기 어렵습니다. 위에서 보셨던 데이터 샘플과 같이, 입력과 출력간 시간 정렬이 정확하지 않습니다. (대표적인 피아노 오디오-MIDI 데이터셋인 MAESTRO [6] 의 경우, 시간오차가 3ms이내로 매우 정확한 것과 비교하면 큰 차이입니다.)
3.
데이터를 수집하기가 어렵습니다. 원래도 MIR에서는 음악 데이터를 구하기 어려운데, 피아노 편곡과 그에 대응하는 팝 음악을 수집하는 것은 더욱 어렵습니다. 온라인에서 수집하는 데이터로서의 피아노 편곡은 원곡의 진행을 편곡자가 수정하는 경우가 매우 많습니다. 이런 부분이 데이터의 노이즈가 되어 양질의 데이터를 대량으로 구하기 어렵게 합니다.
Music Generation과도 비슷하다 할 수 있습니다. MIDI Domain에서 MIDI Sequence를 생성하는 연구[2, 7, 8] 나, Raw Music Audio에서 음악을 생성하는 연구 [9] 등이 그것입니다. 그러나 이러한 작업들은 입출력의 형태나 목적이 달라 같은 방법을 적용하기는 어렵습니다.
그러나 우리가 아는 한 Raw Music Audio를 조건부로 그에 맞는 음악을 생성하는 연구는 없었습니다.
4. Conclusion
우리의 연구는 아직 나아갈 길이 멀지만, 조만간 좋은 결과로 학회에서 만날 수 있기를 바랍니다.
5. References
[1] Jongpil Lee, Jiyoung Park, Keunhyoung Luke Kim, & Juhan Nam. (2017). Sample-level Deep Convolutional Neural Networks for Music Auto-tagging Using Raw Waveforms.
[2] Yu-Siang Huang, & Yi-Hsuan Yang. (2020). Pop Music Transformer: Beat-based Modeling and Generation of Expressive Pop Piano Compositions.
[3] Curtis Hawthorne, Erich Elsen, Jialin Song, Adam Roberts, Ian Simon, Colin Raffel, Jesse Engel, Sageev Oore, & Douglas Eck. (2018). Onsets and Frames: Dual-Objective Piano Transcription.
[4] Jong Wook Kim, & Juan Pablo Bello. (2019). Adversarial Learning for Improved Onsets and Frames Music Transcription.
[5] Curtis Hawthorne, Ian Simon, Rigel Swavely, Ethan Manilow, & Jesse Engel. (2021). Sequence-to-Sequence Piano Transcription with Transformers.
[6] Curtis Hawthorne, Andriy Stasyuk, Adam Roberts, Ian Simon, Cheng-Zhi Anna Huang, Sander Dieleman, Erich Elsen, Jesse Engel, & Douglas Eck. (2019). Enabling Factorized Piano Music Modeling and Generation with the MAESTRO Dataset.
[7] Hao-Min Liu, & Yi-Hsuan Yang. (2018). Lead Sheet Generation and Arrangement by Conditional Generative Adversarial Network.
[8] Muhamed, A., Li, L., Shi, X., Yaddanapudi, S., Chi, W., Jackson, D., Suresh, R., Lipton, Z., & Smola, A. (2021). Symbolic Music Generation with Transformer-GANs.
[9] Prafulla Dhariwal, Heewoo Jun, Christine Payne, Jong Wook Kim, Alec Radford, & Ilya Sutskever. (2020). Jukebox: A Generative Model for Music.
 sweetcocoa@snu.ac.kr
sweetcocoa@snu.ac.kr