
Research Overview
Human perception is a higher level process than sensation. We can get information from a variety of sensory organs, including sight, tactile, and hearing, but their perception is ultimately integrated through people’s thinking processes.
However, most artificial intelligence systems are now focusing on only one sensory information. Extract and generate information from a single modality such as image, audio, and text information. Our goal is to find associations between these multiple modalities and to convey mutual information.
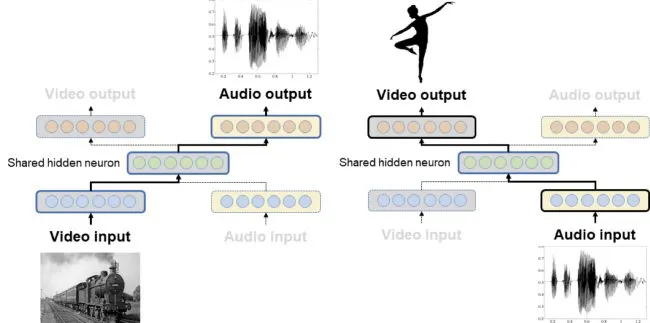
Figure 1. Concept of the system
Our first approach is to create single modal information with constraints on complex information, just as it is to make another music based on music. We plan to expand into multi modality studies such as generating images from sound or creating images from sound.
Publication
•
Lee, Juheon, Seohyun Kim, and Kyogu Lee. “Listen to Dance: Music-driven choreography generation using Autoregressive Encoder-Decoder Network.” arXiv preprint arXiv:1811.00818(2018).